

OpenAI于2025年4月14日推出了GPT-4.1模型系列,包含三个新模型:GPT-4.1、GPT-4.1 mini和GPT-4.1 nano。这些模型在编码、指令遵循和长上下文理解方面表现出色,特别是在编码任务中相较于之前的GPT-4o模型提升显著。GPT-4.1具备更大的上下文窗口,最大支持100万个标记,适合处理大规模代码库和长文档。其改进在于指令跟随的可靠性和长上下文理解能力,使其在实际应用中更为有效。此外,GPT-4.1的反应速度和成本效率也有显著优化,尤其适用于需要低延迟服务的任务。
原文链接:https://openai.com/index/gpt-4-1/

以下是原文翻译
今天,我们在 API 中推出了三个新模型:GPT‑4.1、GPT‑4.1 mini 和 GPT‑4.1 nano。这些模型在各方面都优于 GPT‑4o 和 GPT‑4o mini,在编码和指令跟随方面取得了重大进展。它们还拥有更大的上下文窗口,支持多达 100 万个标记的上下文,并且能够通过改进的长上下文理解更好地利用这些上下文。 它们具有截至 2024 年 6 月的更新知识库。
GPT‑4.1 在以下行业标准衡量指标上表现出色:
编码 :GPT‑4.1 在 SWE-bench 验证 中得分 54.6%,相比 GPT‑4o 提高了 21.4% 绝对值 ,并比 GPT‑4.5 高出 26.6% 绝对值 ,使其成为领先的编程模型。
指令遵循: 在 Scale 的 MultiChallenge 基准测试中,该测试衡量指令遵循能力,GPT‑4.1 得分 38.3%,比 GPT‑4o 高出 10.5%。
长上下文: 在 Video-MME 上,这是一个评估多模态长上下文理解的基准测试,GPT‑4.1 创造了新的最先进结果 - 在长视频无字幕类别中得分 72.0%,比 GPT‑4o 提高了 6.7%。
尽管基准测试提供了宝贵的洞察,但我们训练这些模型的重点是实际应用效用。通过与开发者社区密切合作和伙伴关系,我们能够针对对其应用最重要的任务优化这些模型。
为此,GPT-4.1 模型系列在降低成本的同时提供了卓越的性能。这些模型在每个延迟曲线点上都推进了性能。
GPT‑4.1 mini 在小型模型性能方面实现了重大飞跃,在许多基准测试中甚至超越了 GPT‑4o。它在智能评估中与 GPT‑4o 相匹配或更优,同时将延迟几乎减半,成本降低 83%。
对于需要低延迟的任务,GPT-4.1 纳米是我们可用的最快且最便宜的模型。它在小型尺寸下提供出色性能,拥有 100 万个令牌的上下文窗口,在 MMLU 上得分 80.1%,GPQA 得分 50.3%,Aider 多语言编程得分 9.8%,甚至比 GPT-4o mini 更高。它非常适合分类或自动完成等任务。
这些在指令跟随可靠性和长上下文理解方面的改进,使 GPT-4.1 模型在为用户独立完成任务的代理系统中变得更加有效。当与响应 API 等基础功能相结合时,开发者现在可以构建更加有用且可靠的代理,用于实际软件工程、从大型文档中提取洞察、以最少的人工指导解决客户请求,以及其他复杂任务。
请注意,GPT-4.1 仅通过 API 提供。在 ChatGPT 中,许多在指令跟随、编程和智能方面的改进已逐步整合到最新版本 的 GPT-4o 中,我们将继续在未来的版本中继续纳入更多改进。
我们还将开始在 API 中弃用 GPT-4.5 预览版,因为 GPT-4.1 在许多关键能力上提供了更好或相似的性能,且成本和延迟大幅降低。GPT-4.5 预览版将在三个月后的 2025 年 7 月 14 日关闭,以便开发者有时间过渡。GPT-4.5 作为研究预览版引入,目的是探索和试验一个计算密集型大型模型,我们从开发者反馈中获得了很多见解。我们将继续在未来的 API 模型中延续 GPT-4.5 中您所欣赏的创造力、写作质量、幽默感和细微差别。
下面,我们将详细分析 GPT-4.1 在几个基准测试中的表现,并展示来自 Windsurf、Qodo、Hex、Blue J、汤姆森路透和卡莱尔等阿尔法测试者的示例,展示其在特定领域任务的生产性能。
编码
在各种编码任务中,GPT-4.1 显著优于 GPT-4o,包括主动解决编码任务、前端编码、减少不必要的编辑、可靠地遵循差异格式、确保一致的工具使用等。
在衡量真实世界软件工程技能的 SWE-bench Verified 测试中,GPT-4.1 完成了 54.6%的任务,而 GPT-4o 仅完成了 33.2%(截至 2024-11-20)。这反映了模型在探索代码仓库、完成任务以及生成能运行并通过测试的代码方面的能力提升。

对于 SWE-bench 验证 ,模型会获得一个代码仓库和问题描述,并且必须生成一个补丁来解决该问题。性能高度依赖于使用的提示词和工具。为了帮助复现和语境化我们的结果,我们在此处描述了 GPT-4.1 的设置。我们的分数排除了 500 个问题中的 23 个,这些问题的解决方案无法在我们的基础设施上运行;如果这些问题保守地评分为 0,则 54.6%的分数将变为 52.1%。
对于需要编辑大型文件的 API 开发者来说,GPT-4.1 在跨多种格式的代码差异方面更加可靠。GPT-4.1 的得分超过了 GPT-4o 在 Aider 的多语言差异基准测试中的两倍多,甚至比 GPT-4.5 高出 8% 个百分点 。这次评估既是衡量跨各种编程语言编码能力的指标,也是衡量模型生成整体和差异格式变更的能力。我们专门训练了 GPT-4.1 以更可靠地遵循差异格式,这使开发者能够通过仅输出变更的行来节省成本和延迟,而不是重写整个文件。欲获得最佳代码差异性能,请参考我们的提示词指南 。对于更喜欢重写整个文件的开发者,我们已将 GPT-4.1 的输出令牌限制增加到 32,768 个令牌(从 GPT-4o 的 16,384 个令牌提升)。我们还建议使用预测输出以减少完整文件重写的延迟。

在 Aider 的多语言基准测试中,模型通过编辑源文件解决 Exercism 的编码练习,允许重试一次。"whole"格式要求模型重写整个文件,这可能会很慢且代价高昂。"diff"格式要求模型编写一系列搜索/替换块.
GPT-4.1 在前端编码方面也大幅改进,能够创建更加功能性强且美观的网络应用。在我们的对比测试中,付费人工评分员在 80%的情况下更喜欢 GPT-4.1 的网站,而非 GPT-4o 的网站。
提示: 制作一个闪卡网页应用。用户应该能够创建闪卡、搜索现有的闪卡、复习闪卡,并查看闪卡复习的统计信息。预加载十张包含印地语单词或短语及其英文翻译的卡片。复习界面:在复习界面,单击或按空格键应该以平滑的 3D 动画翻转卡片以显示翻译。按箭头键应该可以浏览卡片。搜索界面:搜索栏应该在用户输入查询时动态提供结果列表。统计界面:统计页面应显示用户已复习的卡片数量图表,以及正确率。创建卡片界面:创建卡片页面应允许用户指定闪卡的正面和反面,并将其添加到用户的卡片集中。这些界面都应该可以通过侧边栏访问。生成一个单页 React 应用(内联所有样式)。
除了上述基准测试,GPT-4.1 在更可靠地遵循格式并更少地进行无关编辑方面表现更佳。在我们的内部评估中,代码的无关编辑从 GPT-4o 的 9%下降到 GPT-4.1 的 2%。
真实世界的示例
帆板:GPT-4.1 在 Windsurf 的内部编码基准测试中得分比 GPT-4o 高 60%,该基准与代码更改在首次审查中被接受的频率强烈相关。他们的用户注意到,在工具调用方面效率提高了 30%,在重复不必要的编辑或以过于狭窄、增量的步骤阅读代码方面减少了约 50%。这些改进使工程团队能够更快地迭代并获得更流畅的工作流程。
Qodo:Qodo 在 GitHub 拉取请求中,使用受其微调基准启发的方法,将 GPT‑4.1 与其他领先模型进行了逐一测试,以生成高质量的代码审查。在 200 个有意义的真实世界拉取请求中,使用相同的提示和条件,他们发现 GPT‑4.1 在 55% 的情况下提供了更好的建议。值得注意的是,他们发现 GPT‑4.1 在精确性(知道何时不提建议)和全面性(在需要时提供全面分析)方面都表现出色,同时始终关注最关键的问题。
指令跟随
GPT-4.1 在指令跟随方面更加可靠,我们在多个指令跟随评估中测量到显著的改进。
我们开发了一个内部指令跟随评估系统,以跟踪模型在多个维度和几个关键指令跟随类别中的性能表现。
按以下格式操作。 为模型的响应提供指定自定义格式的指令,如 XML、YAML、Markdown 等。
负面指令。 指定模型应避免的行为。(示例:"不要要求用户联系支持")
有序指令。 提供模型必须按特定顺序遵循的一组指令。(示例:"先询问用户的姓名,然后询问他们的电子邮件")
内容要求。 输出包含特定信息的内容。(示例:"在编写营养计划时始终包含蛋白质的数量")
排名。 以特定方式对输出进行排序。(示例:"按人口数量排序")
过度自信。 指示模型在请求的信息不可用或请求不符合给定类别时说"我不知道"或类似的话。(示例:"如果您不知道答案,请提供支持联系人的电子邮件")
这些类别是根据开发者关于指令遵循最相关和重要的方面的反馈得出的。在每个类别中,我们将提示分为简单、中等和困难三个等级。GPT-4.1 在困难提示方面,特别是在改进方面,显著超过了 GPT-4o。

我们的内部指令遵循评估基于真实的开发者使用案例和反馈,涵盖了不同复杂程度的任务,并包括有关格式、详细程度、长度等的指令。
多轮指令跟随对许多开发者来说至关重要——模型能够在对话深处保持连贯性,并跟踪用户之前告诉它的内容非常重要。我们训练 GPT‑4.1 能更好地从对话中过去的消息中提取信息,从而实现更自然的对话。来自 Scale 的 MultiChallenge 基准是衡量这种能力的有用指标,GPT‑4.1 比 GPT‑4o 表现提高了 10.5%abs。

GPT-4.1 在 IFEval 上得分为 87.4%,而 GPT-4o 为 81.0%。IFEval 使用带有可验证指令的提示(例如,指定内容长度或避免某些术语或格式)。
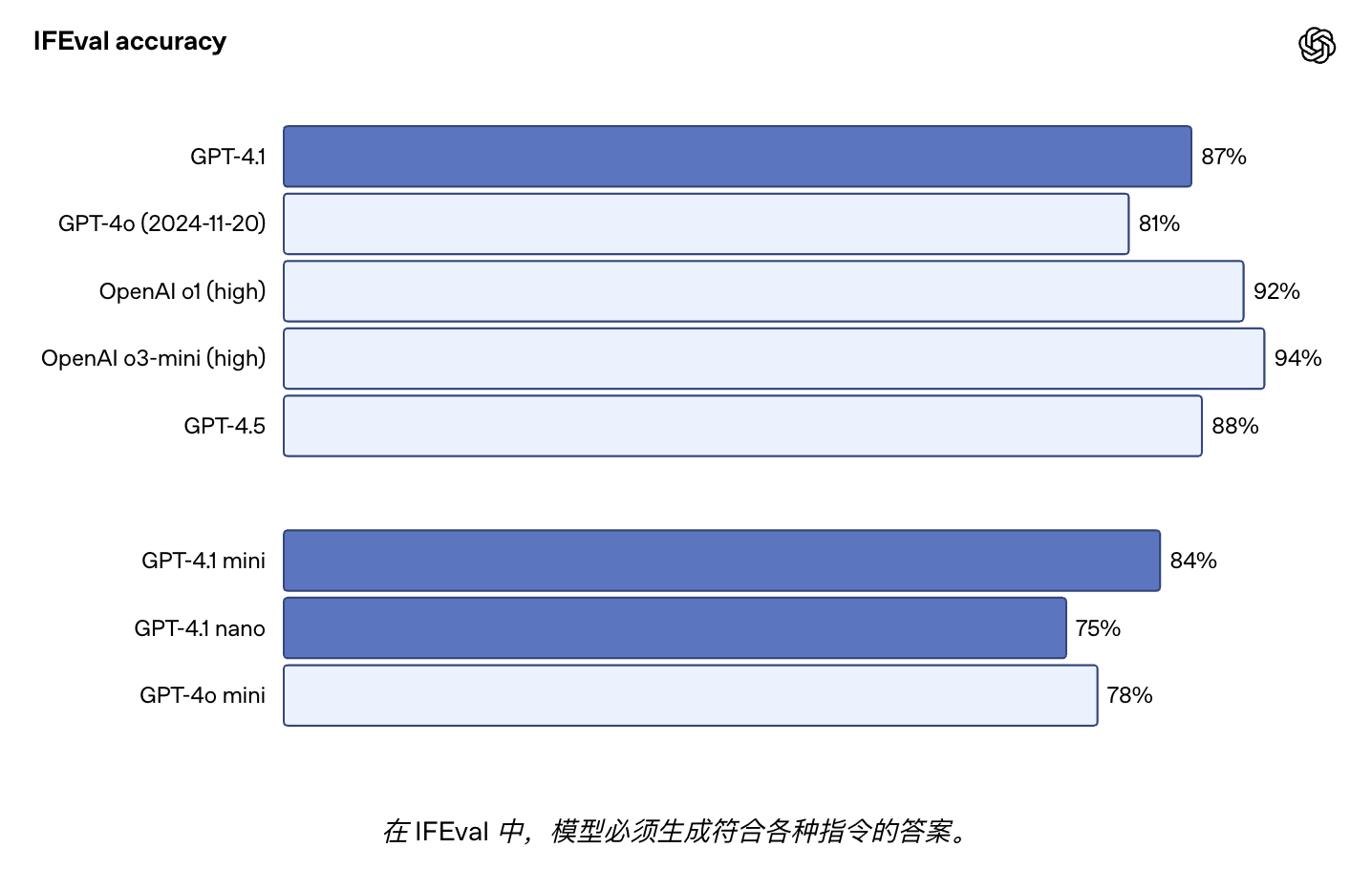
更好的指令遵循使现有应用程序更加可靠,并使之前因可靠性较低而受限的新应用程序成为可能。早期测试者注意到 GPT-4.1 可以更加字面,因此我们建议在提示中要明确和具体。关于 GPT-4.1 的提示最佳实践,请参考提示指南。
真实世界的示例
Blue J: 在 Blue J 最具挑战性的真实税务场景的内部基准测试中,GPT-4.1 比 GPT-4o 的准确率提高了 53%。这一准确率的跃升——对系统性能和用户满意度至关重要——凸显了 GPT-4.1 对复杂法规的更强理解能力,以及在长上下文中遵循细微指令的能力。对于 Blue J 用户来说,这意味着更快速、更可靠的税务研究,并能腾出更多时间进行高价值的咨询工作。
Hex:GPT-4.1 在 Hex 最具挑战性的 SQL 评估集上几乎带来了 2 倍的改进 , 展示了指令遵循和语义理解方面的显著进步。该模型在从大型、模糊的模式中选择正确表格方面更加可靠——这是一个上游决策点,直接影响整体准确性,并且很难仅通过提示来调整。对于 Hex 来说,这导致手动调试工作的可测量减少,并加快了通向生产级工作流的路径。
长上下文
GPT‑4.1、GPT‑4.1 mini 和 GPT‑4.1 nano 可以处理多达 100 万个标记的上下文,相比之前的 GPT‑4o 模型的 12.8 万个标记。100 万个标记相当于整个 React 代码库的 8 个完整副本,因此长上下文非常适合处理大型代码库或大量长文档。
我们训练了 GPT‑4.1,使其能可靠地关注整个 100 万个标记长度的信息。我们还训练它比 GPT‑4o 更可靠地注意相关文本,并在长短上下文中忽略干扰信息。长上下文理解对于法律、编码、客户支持和许多其他领域的应用至关重要。
下面,我们展示了 GPT‑4.1 在上下文窗口不同位置查找小型隐藏信息("针")的能力。GPT‑4.1 始终能准确地在所有位置和所有上下文长度(直到 100 万个标记)检索到这个"针"。它能够有效地提取任务所需的相关细节,无论这些细节在输入中的位置如何。
然而,很少有真实世界的任务像检索单一明显的答案那样直接。我们发现用户通常需要模型检索和理解多个信息片段,并理解这些片段之间的关系。为了展示这种能力,我们正在开源一个新的评估:OpenAI-MRCR(多轮共指)。
OpenAI-MRCR 测试模型在深藏在上下文中的多个目标之间查找和消歧的能力。评估由用户和助手之间的多轮合成对话组成,用户要求撰写关于某个主题的文章,例如"写一首关于貘的诗"或"写一篇关于岩石的博客文章"。然后我们在上下文中插入两个、四个或八个相同的请求。模型必须检索对应于特定实例的响应(例如,"给我第三首关于貘的诗")。
挑战源于这些请求与其余上下文之间的相似性——模型很容易被细微的差异误导,比如关于貘的短篇故事而不是诗歌,或者关于青蛙而不是貘的诗歌。我们发现 GPT-4.1 在长度高达 128K 个标记的上下文中表现优于 GPT-4o,并且即使在长达 100 万个标记的情况下也保持强劲的性能。
但这个任务仍然很困难——即使对于高级推理模型来说。我们正在共享评估数据集 以鼓励在真实世界长上下文检索方面进行更多研究。

我们还发布了 Graphwalks,这是一个用于评估多跳长上下文推理的数据集。许多开发者使用长上下文的场景需要在上下文中进行多次逻辑跳转,比如在编写代码时在多个文件之间跳转,或在回答复杂的法律问题时交叉引用文档。
理论上,一个模型(甚至是人)可以通过一次遍历或阅读提示来解决 OpenAI-MRCR 问题,但 Graphwalks 设计为需要在上下文的多个位置进行推理,并且无法顺序解决。
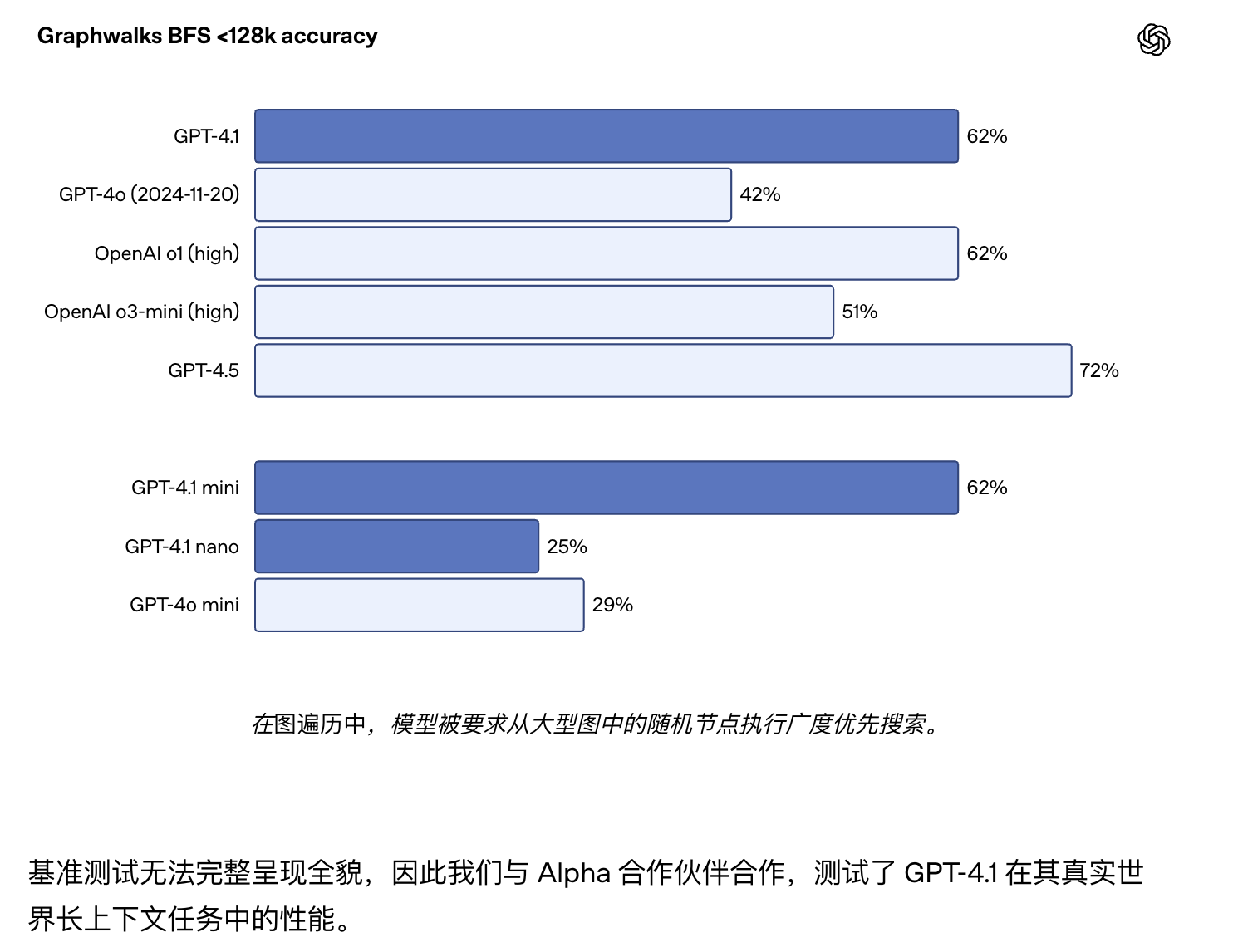
Graphwalks 使用由十六进制哈希组成的有向图填充上下文窗口,然后要求模型从图中的随机节点开始执行广度优先搜索(BFS)。然后要求它返回特定深度的所有节点。GPT-4.1 在这个基准测试中达到了 61.7%的准确率,与 o1 的性能相匹配,并轻松击败 GPT-4o。
真实世界的示例
汤姆森路透社:汤姆森路透社使用 CoCounsel(他们专业级的法律工作人工智能助手)测试了 GPT-4.1。与 GPT-4o 相比,他们能够在内部长上下文基准测试中将多文档审查准确性提高了 17%——这对评估 CoCounsel 处理涉及多个冗长文档的复杂法律工作流程的能力至关重要。特别是,他们发现该模型在跨来源维持上下文和准确识别文档之间细微的关系(如冲突条款或额外补充上下文)方面非常可靠,这些任务对法律分析和决策至关重要。
Carlyle:Carlyle 使用 GPT-4.1 准确地从多个冗长的文档(包括 PDF、Excel 文件和其他复杂格式)中提取精细的财务数据。根据他们的内部评估,它在从包含大量密集数据的文档中检索信息方面性能提高了 50%,并且是第一个成功克服其他可用模型关键限制的模型,包括海针检索、中间信息丢失错误以及跨文档的多跳推理。
除了模型性能和准确性,开发者还需要能快速响应以满足用户需求的模型。我们已改进推理堆栈以减少首个标记的时间,通过提示缓存,您可以进一步降低延迟并节省成本。在初步测试中,GPT-4.1 的首个标记的 p95 延迟在 128,000 个标记的上下文中约为 15 秒,对于百万个标记的上下文,延迟可达半分钟。GPT-4.1 mini 和 nano 的速度更快,例如 GPT-4.1 nano 大多数情况下能在 5 秒内为 128,000 个输入标记的查询返回首个标记。
视觉
GPT-4.1 家族在图像理解方面极其强大,特别是 GPT-4.1 mini 在图像基准测试中经常击败 GPT-4o,代表了一个重大进步。





结论
GPT-4.1 是人工智能实际应用的重要进步。通过密切关注开发者的实际需求——从编码到指令跟随和长上下文理解——这些模型为构建智能系统和复杂的智能应用解锁了新的可能性。我们一直受到开发者社区创造力的启发,并期待看到您用 GPT-4.1 构建的成果。